

One of the key attributes of Bayesian analysis is its ability to incorporate prior information with the aim of improving the quality of inferences and predictions. Prior information comes in two primary forms: a model for the data generating process often called a likelihood, in which we try to incorporate the latest understanding of the underlying process (e.g. how cancer spreads through the body) and a prior distribution of all the unknowns in the system (e.g. the growth rate of cells that are resistant to treatment), which often rules out the values of the parameters that are inconsistent with that understanding. It is important to note that prior distributions are always there, whether specified or not, and so we must do our best to write them down explicitly so that they can be examined, assessed, and criticized.
The question arises as to the source of these priors. There is no prescribed methodology for obtaining them but generally, priors come from previous experiments, computational considerations, or subject matter experts. In this document, we will focus on the latter category.
Eliciting prior information from experts has a rich history in academic literature, see for example [3], and have been applied in practice in the context of clinical trials, see for example [2]. Several methods are summarized in Chapter 5 of "Bayesian Methods in Pharmaceutical Research" [1] but here we will focus on the codified framework called SHELF (SHeffield ELicitation Framework) [4].
The framework consists of two main parts: 1) eliciting probabilistic judgments for the quantity or quantities of interest (i.e. parameters) 2) constructing parametric distribution from these judgments that are often given in terms of quartiles and combining them into a single "consensus"1 distribution. The first part has to be done interactively with one or more experts and typically requires some training for the experts to be effective. An online course has been developed for this purpose and is available at http://tonyohagan.co.uk/shelf/ecourse.html. In addition, a set of guidelines have been developed for eliciting the priors. See, for instance, Figure 1 showing the example of eliciting the first quartile Q1 (i.e. Q1 is the value of the parameter such that the probability of the true value being less than Q1 is 25%).

During the interactive session, the facilitator guides the experts through a process of picking the median value, first, and third quartiles, and upper and lower plausible limits for the parameter in question. The second part of the process, namely fitting distributions to elicited quantiles is described in the following example.
Suppose that two investigators have been working on a new therapy for which some preliminary data have become available from an early Phase II trial. Also, suppose that the investigators are experts in this class of drugs and have informed opinions about the potential efficacy of this candidate relative to the current standard of care. We would like to elicit the plausible values of the Hazard Ratio should a large Phase III trial be undertaken. Suppose that after the facilitated group session, two experts provided the quartiles for the Hazard Ratio depicted in Figure 2 which is generated using an R package SHELF [5].
You can see that expert B is slightly more optimistic about the outcome than expert A providing slightly lower values of the Hazard Ratio on average. Depending on their experience we may give more or less weight to expert A when pooling the results. Once the quartiles are entered, we fit a distribution to each expert and combine the two (or more) distributions in a single "consensus" distribution as demonstrated in Figure 3.
We don't recommend using the elicited priors directly for decision making but rather as a prior distribution to a full Bayesian analysis. The reason is that priors, formally $p(\theta)$ in the statistics literature, are generally extremely imprecise estimates of the treatment effect. After all, if that were not the case, why perform any experiments at all! The purpose of the priors is to sufficiently constrain the system, so that a model, formally $p(y \mid \theta)$, can be identified with a limited amount of data $y$. Once, these data had been observed, we update $p(\theta)$ with this new information to obtain $p(\theta \mid y)$ called a posterior distribution, which will give us a much better estimate of $\theta$ (Hazard Ratio in our case), the parameter in question. The more data we collect, the less influence $p(\theta)$ will exert on the posterior distribution.
In an effort to use all available information for some of the most consequential decisions in the drug development process, it would be helpful to solicit input from those people who are most familiar with the drug development program. Even though the process and tools for eliciting this information have been developed and validated in the literature and industry, it has not been yet been adopted in many pharmaceutical programs. The same can be said about Bayesian methods and we believe that significant improvement over the status quo can be achieved by putting them into practice.
[1] Casoli, Carl Di, Yueqin Zhao, Yannis Jemiai, Pritibha Singh, and Maria Costa. 2020. “Bayesian Methods in Pharmaceutical Research.” In, 329–44. Chapman; Hall/CRC. https://doi.org/10.1201/9781315180212-17.
[2] Dallow, Nigel, Nicky Best, and Timothy H Montague. 2018. “Better Decision Making in Drug Development Through Adoption of Formal Prior Elicitation.” Pharmaceutical Statistics 17 (4): 301–16. https://doi. org/10.1002/pst.1854.
[3] O’Hagan, A. 1998. “Eliciting Expert Beliefs in Substantial Practical Applications [Read Before The Royal Statistical Society at Ameeting on ’Elicitation’ on Wednesday, April 16th, 1997, the President, Professor A. F. M. Smithin the Chair].” Journal of the Royal Statistical Society: Series D (The Statistician) 47 (1): 21–35. https://doi.org/10.1111/1467-9884.00114.
[4] O’Hagan, Tony, and Jeremy Oakley. 2019. “SHELF: The Sheffield Elicitation Framework.” http://tonyohagan. co.uk/shelf/.
[5] Oakley, Jeremy. 2021. SHELF: Tools to Support the Sheffield Elicitation Framework. https://CRAN.R- project.org/package=SHELF.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.
This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.

Trying to cut corners to make nonlinear PK model fitting faster

.svg)
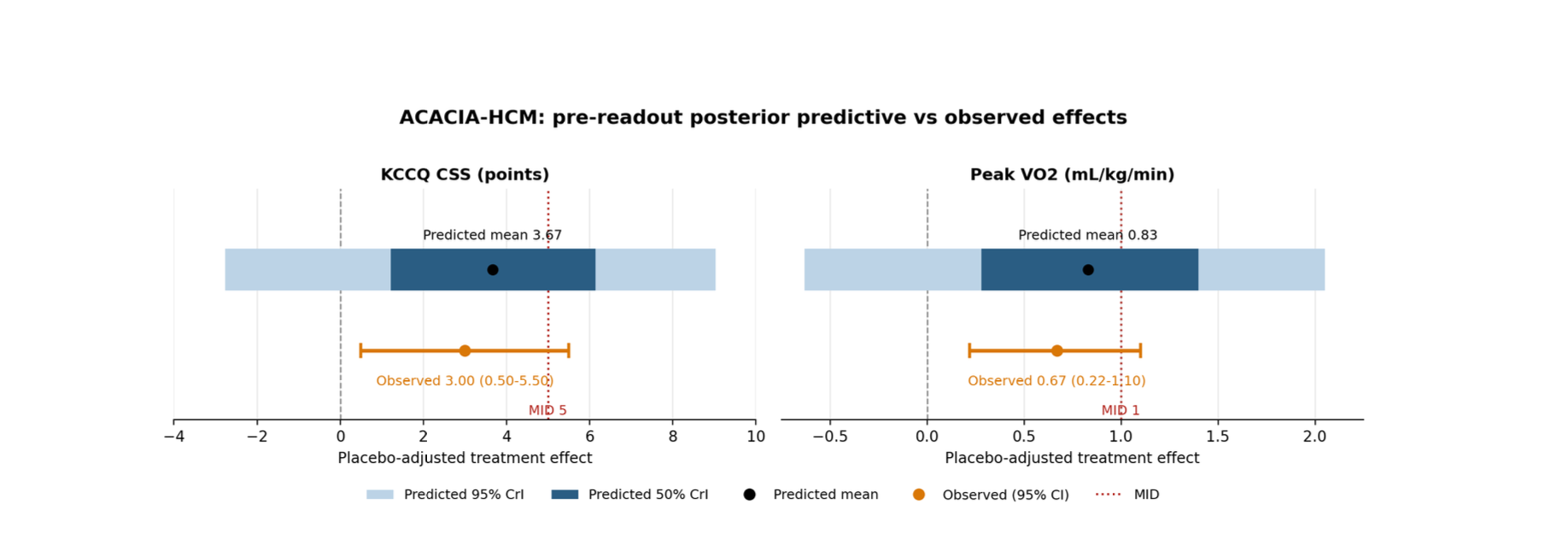

This is a comment related to the post above. It was submitted in a form, formatted by Make, and then approved by an admin. After getting approved, it was sent to Webflow and stored in a rich text field.